
Moving from Lilo to GRUB, using LVM as default, etc throughout the last years it was time to evaluate how well LVM works
without a separate boot partition, possibly also on top of Software RAID. Big disks are asking for partitioning with
GPT, just
UEFI isn t my default
yet, so I m still defaulting to Legacy BIOS for Debian/wheezy (I expect this to change for Debian/jessie and according hardware approaching at my customers).
So what we have and want in this demonstration setup:
- Debian 7 AKA wheezy
- 4 hard-disks with Software RAID (on 8GB RAM), using GPT partitioning + GRUB2
- using state-of-the-art features without too much workarounds like separate /boot partition outside of LVM or mdadm with 0.9 metadata, just no (U)EFI yet
- LVM on top of SW-RAID (RAID5) for /boot partition [SW-RAID->LVM]
- Cryptsetup-LUKS on top of LVM on top of SW-RAID (RAID5) for data [SW-RAID->LVM->Crypto] (this gives us more flexibility about crypto yes/no and different cryptsetup options for the LVs compared to using it below RAID/LVM)
- Rescue-system intregration via grml-rescueboot (not limited to Grml, but Grml should work out-of-the-box)
System used for installation:
root@grml ~ # grml-version
grml64-full 2013.09 Release Codename Hefeknuddler [2013-09-27]
Partition setup:
root@grml ~ # parted /dev/sda
GNU Parted 2.3
Using /dev/sda
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) mklabel gpt
(parted) mkpart primary 2048s 4095s
(parted) set 1 bios_grub on
(parted) name 1 "BIOS Boot Partition"
(parted) mkpart primary 4096s 100%
(parted) set 2 raid on
(parted) name 2 "SW-RAID / Linux"
(parted) quit
Information: You may need to update /etc/fstab.
Clone partition layout from sda to all the other disks:
root@grml ~ # for f in b,c,d ; sgdisk -R=/dev/sd$f /dev/sda
The operation has completed successfully.
The operation has completed successfully.
The operation has completed successfully.
Make sure each disk has its unique UUID:
root@grml ~ # for f in b,c,d ; sgdisk -G /dev/sd$f
The operation has completed successfully.
The operation has completed successfully.
The operation has completed successfully.
SW-RAID setup:
root@grml ~ # mdadm --create /dev/md0 --verbose --level=raid5 --raid-devices=4 /dev/sd a,b,c,d 2
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: size set to 1465004544K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
root@grml ~ #
SW-RAID speedup (system dependent,
YMMV):
root@grml ~ # cat /sys/block/md0/md/stripe_cache_size
256
root@grml ~ # echo 16384 > /sys/block/md0/md/stripe_cache_size # 16MB
root@grml ~ # blockdev --getra /dev/md0
6144
root@grml ~ # blockdev --setra 65536 /dev/md0 # 32 MB
root@grml ~ # sysctl dev.raid.speed_limit_max
dev.raid.speed_limit_max = 200000
root@grml ~ # sysctl -w dev.raid.speed_limit_max=9999999999
dev.raid.speed_limit_max = 9999999999
root@grml ~ # sysctl dev.raid.speed_limit_min
dev.raid.speed_limit_min = 1000
root@grml ~ # sysctl -w dev.raid.speed_limit_min=100000
dev.raid.speed_limit_min = 100000
LVM setup:
root@grml ~ # pvcreate /dev/md0
Physical volume "/dev/md0" successfully created
root@grml ~ # vgcreate homesrv /dev/md0
Volume group "homesrv" successfully created
root@grml ~ # lvcreate -n rootfs -L4G homesrv
Logical volume "rootfs" created
root@grml ~ # lvcreate -n bootfs -L1G homesrv
Logical volume "bootfs" created
Check partition setup + alignment:
root@grml ~ # parted -s /dev/sda print
Model: ATA WDC WD15EADS-00P (scsi)
Disk /dev/sda: 1500GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name Flags
1 1049kB 2097kB 1049kB BIOS Boot Partition bios_grub
2 2097kB 1500GB 1500GB SW-RAID / Linux raid
root@grml ~ # parted -s /dev/sda unit s print
Model: ATA WDC WD15EADS-00P (scsi)
Disk /dev/sda: 2930277168s
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name Flags
1 2048s 4095s 2048s BIOS Boot Partition bios_grub
2 4096s 2930276351s 2930272256s SW-RAID / Linux raid
root@grml ~ # gdisk -l /dev/sda
GPT fdisk (gdisk) version 0.8.5
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT.
Disk /dev/sda: 2930277168 sectors, 1.4 TiB
Logical sector size: 512 bytes
Disk identifier (GUID): 212E463A-A4E3-428B-B7E5-8D5785141564
Partition table holds up to 128 entries
First usable sector is 34, last usable sector is 2930277134
Partitions will be aligned on 2048-sector boundaries
Total free space is 2797 sectors (1.4 MiB)
Number Start (sector) End (sector) Size Code Name
1 2048 4095 1024.0 KiB EF02 BIOS Boot Partition
2 4096 2930276351 1.4 TiB FD00 SW-RAID / Linux
root@grml ~ # mdadm -E /dev/sda2
/dev/sda3:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 7ed3b741:0774d529:d5a71c1f:cf942f0a
Name : grml:0 (local to host grml)
Creation Time : Fri Jan 31 15:26:12 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 2928060416 (1396.21 GiB 1499.17 GB)
Array Size : 4392089088 (4188.62 GiB 4497.50 GB)
Used Dev Size : 2928059392 (1396.21 GiB 1499.17 GB)
Data Offset : 262144 sectors
Super Offset : 8 sectors
State : clean
Device UUID : c1e4213b:81822fd1:260df456:2c9926fb
Update Time : Mon Feb 3 09:41:48 2014
Checksum : b8af8f6 - correct
Events : 72
Layout : left-symmetric
chunk size : 512k
Device Role : Active device 0
Array State : AAAA ('A' == active, '.' == missing)
root@grml ~ # pvs -o +pe_start
PV VG Fmt Attr PSize PFree 1st PE
/dev/md0 homesrv lvm2 a-- 4.09t 4.09t 1.50m
root@grml ~ # pvs --units s -o +pe_start
PV VG Fmt Attr PSize PFree 1st PE
/dev/md0 homesrv lvm2 a-- 8784175104S 8773689344S 3072S
root@grml ~ # pvs -o +pe_start
PV VG Fmt Attr PSize PFree 1st PE
/dev/md0 homesrv lvm2 a-- 4.09t 4.09t 1.50m
root@grml ~ # pvs --units s -o +pe_start
PV VG Fmt Attr PSize PFree 1st PE
/dev/md0 homesrv lvm2 a-- 8784175104S 8773689344S 3072S
root@grml ~ # vgs -o +pe_start
VG #PV #LV #SN Attr VSize VFree 1st PE
homesrv 1 2 0 wz--n- 4.09t 4.09t 1.50m
root@grml ~ # vgs --units s -o +pe_start
VG #PV #LV #SN Attr VSize VFree 1st PE
homesrv 1 2 0 wz--n- 8784175104S 8773689344S 3072S
Cryptsetup:
root@grml ~ # echo cryptsetup >> /etc/debootstrap/packages
root@grml ~ # cryptsetup luksFormat -c aes-xts-plain64 -s 256 /dev/mapper/homesrv-rootfs
WARNING!
========
This will overwrite data on /dev/mapper/homesrv-rootfs irrevocably.
Are you sure? (Type uppercase yes): YES
Enter passphrase:
Verify passphrase:
root@grml ~ # cryptsetup luksOpen /dev/mapper/homesrv-rootfs cryptorootfs
Enter passphrase for /dev/mapper/homesrv-rootfs:
Filesystems:
root@grml ~ # mkfs.ext4 /dev/mapper/cryptorootfs
mke2fs 1.42.8 (20-Jun-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=128 blocks, Stripe width=384 blocks
262144 inodes, 1048192 blocks
52409 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1073741824
32 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
root@grml ~ # mkfs.ext4 /dev/mapper/homesrv-bootfs
mke2fs 1.42.8 (20-Jun-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=128 blocks, Stripe width=384 blocks
65536 inodes, 262144 blocks
13107 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=268435456
8 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: done
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
Install Debian/wheezy:
root@grml ~ # mount /dev/mapper/cryptorootfs /media
root@grml ~ # mkdir /media/boot
root@grml ~ # mount /dev/mapper/homesrv-bootfs /media/boot
root@grml ~ # grml-debootstrap --target /media --password YOUR_PASSWORD --hostname YOUR_HOSTNAME
* grml-debootstrap [0.57] - Please recheck configuration before execution:
Target: /media
Install grub: no
Using release: wheezy
Using hostname: YOUR_HOSTNAME
Using mirror: http://http.debian.net/debian
Using arch: amd64
Important! Continuing will delete all data from /media!
* Is this ok for you? [y/N] y
[...]
Enable grml-rescueboot (to have easy access to rescue ISO via GRUB):
root@grml ~ # mkdir /media/boot/grml
root@grml ~ # wget -O /media/boot/grml/grml64-full_$(date +%Y.%m.%d).iso http://daily.grml.org/grml64-full_testing/latest/grml64-full_testing_latest.iso
root@grml ~ # grml-chroot /media apt-get -y install grml-rescueboot
[NOTE: We're installing a daily ISO for grml-rescueboot here because the 2013.09 Grml release doesn't work for this LVM/SW-RAID setup while newer ISOs are working fine already. The upcoming Grml stable release is supposed to work just fine, so you will be able to choose http://download.grml.org/grml64-full_2014.XX.iso by then. :)]
Install GRUB on all disks and adjust crypttab, fstab + initramfs:
root@grml ~ # grml-chroot /media /bin/bash
(grml)root@grml:/# for f in a,b,c,d ; do grub-install /dev/sd$f ; done
(grml)root@grml:/# update-grub
(grml)root@grml:/# echo "cryptorootfs /dev/mapper/homesrv-rootfs none luks" > /etc/crypttab
(grml)root@grml:/# echo "/dev/mapper/cryptorootfs / auto defaults,errors=remount-ro 0 1" > /etc/fstab
(grml)root@grml:/# echo "/dev/mapper/homesrv-bootfs /boot auto defaults 0 0" >> /etc/fstab
(grml)root@grml:/# update-initramfs -k all -u
(grml)root@grml:/# exit
Clean unmounted/removal for reboot:
root@grml ~ # umount /media/boot
root@grml ~ # umount /media/
root@grml ~ # cryptsetup luksClose cryptorootfs
root@grml ~ # dmsetup remove homesrv-bootfs
root@grml ~ # dmsetup remove homesrv-rootfs
NOTE: On a previous hardware installation I had to install GRUB 2.00-22 from Debian/unstable to get GRUB working.
Some metadata from different mdadm and LVM experiments seems to have been left and
confused GRUB 1.99-27+deb7u2 from Debian/wheezy (I wasn t able to reproduce this issue in my VM demo/test setup).
Just in cause you
might experience the following error message, try GRUB >=2.00-22:
# grub-install --recheck /dev/sda
error: unknown LVM metadata header.
error: unknown LVM metadata header.
/usr/sbin/grub-probe: error: cannot find a GRUB drive for /dev/mapper/cryptorootfs. Check your device.map.
Auto-detection of a filesystem of /dev/mapper/cryptorootfs failed.
Try with --recheck.
If the problem persists please report this together with the output of "/usr/sbin/grub-probe --device-map="/boot/grub/device.map"
--target=fs -v /boot/grub" to <bug-grub@gnu.org>
 Open Source Data Center Conference (OSDC) is a conference on open source software in data centers and huge IT environments and will take place in Berlin/Germany in April 2016. I will give a talk titled Continuous Integration in Data Centers Further 3 Years Later there.
I gave a talk titled Continuous Integration in data centers at OSDC in 2013, presenting ways how to realize continuous integration/delivery with Jenkins and related tools. Three years later we gained new tools in our continuous delivery pipeline, including Docker, Gerrit and Goss. Over the years we also had to deal with different problems caused by faster release cycles, a growing team and gaining new projects. We therefore established code review in our pipeline, improved our test infrastructure and invested in our infrastructure automation. In this talk I will discuss the lessons we learned over the last years, demonstrate how a proper continuous delivery pipeline can improve your life and how open source tools like Jenkins, Docker and Gerrit can be leveraged for setting up such an environment.
Hope to see you there!
Open Source Data Center Conference (OSDC) is a conference on open source software in data centers and huge IT environments and will take place in Berlin/Germany in April 2016. I will give a talk titled Continuous Integration in Data Centers Further 3 Years Later there.
I gave a talk titled Continuous Integration in data centers at OSDC in 2013, presenting ways how to realize continuous integration/delivery with Jenkins and related tools. Three years later we gained new tools in our continuous delivery pipeline, including Docker, Gerrit and Goss. Over the years we also had to deal with different problems caused by faster release cycles, a growing team and gaining new projects. We therefore established code review in our pipeline, improved our test infrastructure and invested in our infrastructure automation. In this talk I will discuss the lessons we learned over the last years, demonstrate how a proper continuous delivery pipeline can improve your life and how open source tools like Jenkins, Docker and Gerrit can be leveraged for setting up such an environment.
Hope to see you there!

 After
After  What happened about the
What happened about the 
 Dear
Dear 

 As you can see the configuration also includes a launch script. This script ensures that slaves are set up as needed (provide all the packages and scripts that are required for building) and always get the latest configuration and scripts before starting to serve as Jenkins slave.
Now your setup should be ready for launching Jenkins slaves as needed:
As you can see the configuration also includes a launch script. This script ensures that slaves are set up as needed (provide all the packages and scripts that are required for building) and always get the latest configuration and scripts before starting to serve as Jenkins slave.
Now your setup should be ready for launching Jenkins slaves as needed:
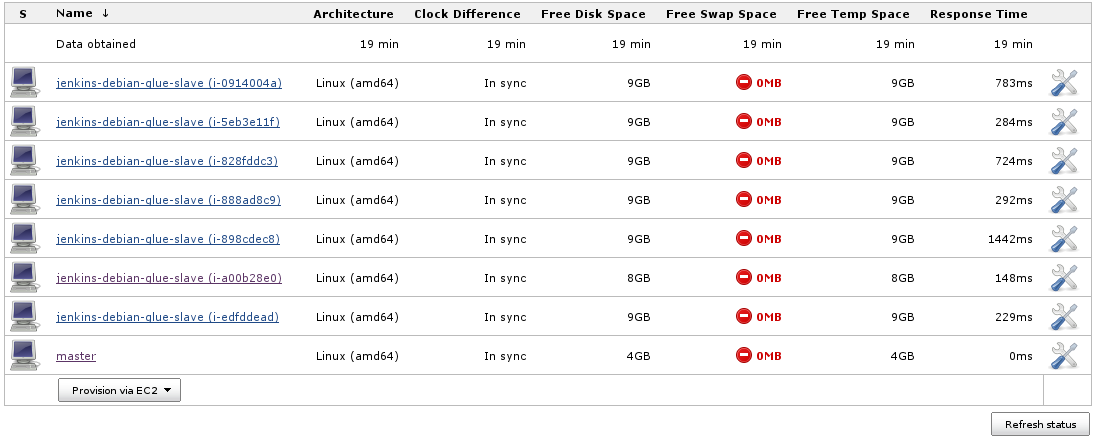 NOTE: you can use the Instance Cap configuration inside the advanced Amazon EC2 Jenkins configuration section to place an upward limit to the number of EC2 instances that Jenkins may launch. This can be useful for avoiding surprises in your AWS invoices.
NOTE: you can use the Instance Cap configuration inside the advanced Amazon EC2 Jenkins configuration section to place an upward limit to the number of EC2 instances that Jenkins may launch. This can be useful for avoiding surprises in your AWS invoices. 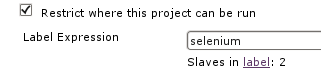 TIP 1: Visiting $JENKINS_SERVER/label/$label/ provides a list of slaves that provide that given $label (as well as list of projects that use $label in their configuration), like:
TIP 1: Visiting $JENKINS_SERVER/label/$label/ provides a list of slaves that provide that given $label (as well as list of projects that use $label in their configuration), like:

 This is what we can use to gradually upgrade from the old Iceweasel version to the new one by keeping a given set of slaves at the old Iceweasel version while we re upgrading other nodes to the new Iceweasel version (same for the selenium-server version which we want to also control). We can include the version number of the Iceweasel and selenium-server packages inside the labels we announce through the swarm slaves, with something like:
This is what we can use to gradually upgrade from the old Iceweasel version to the new one by keeping a given set of slaves at the old Iceweasel version while we re upgrading other nodes to the new Iceweasel version (same for the selenium-server version which we want to also control). We can include the version number of the Iceweasel and selenium-server packages inside the labels we announce through the swarm slaves, with something like:
 Whereas the development selenium job can point to the slaves providing Iceweasel v24, so it will be executed on slave selenium-client1 here:
Whereas the development selenium job can point to the slaves providing Iceweasel v24, so it will be executed on slave selenium-client1 here:
 This setup allowed us to work on the selenium Ruby tests while not conflicting with any production build pipeline. By the time I m writing about this setup we ve already finished the migration to support Iceweasel v24 and the infrastructure is ready for further Iceweasel and selenium-server upgrades.
This setup allowed us to work on the selenium Ruby tests while not conflicting with any production build pipeline. By the time I m writing about this setup we ve already finished the migration to support Iceweasel v24 and the infrastructure is ready for further Iceweasel and selenium-server upgrades.

{kind=link}